CEDNet: Censoring Explicit Details by NeuralNet
Executive Summary
User generated content (UGC) posted by users contributes to the richness and variety of content on the internet. However, these are not subject to editorial controls like traditional media, thus can reach the vulnerable. For instance, exposure to pornographic content has been proven harmful among youth and children. In response, government censorship authorities and social media companies have been exerting efforts to control explicit content on media and on the Internet. The current practice is to hire content moderators who manually review graphic content to determine if it is explicit or not.
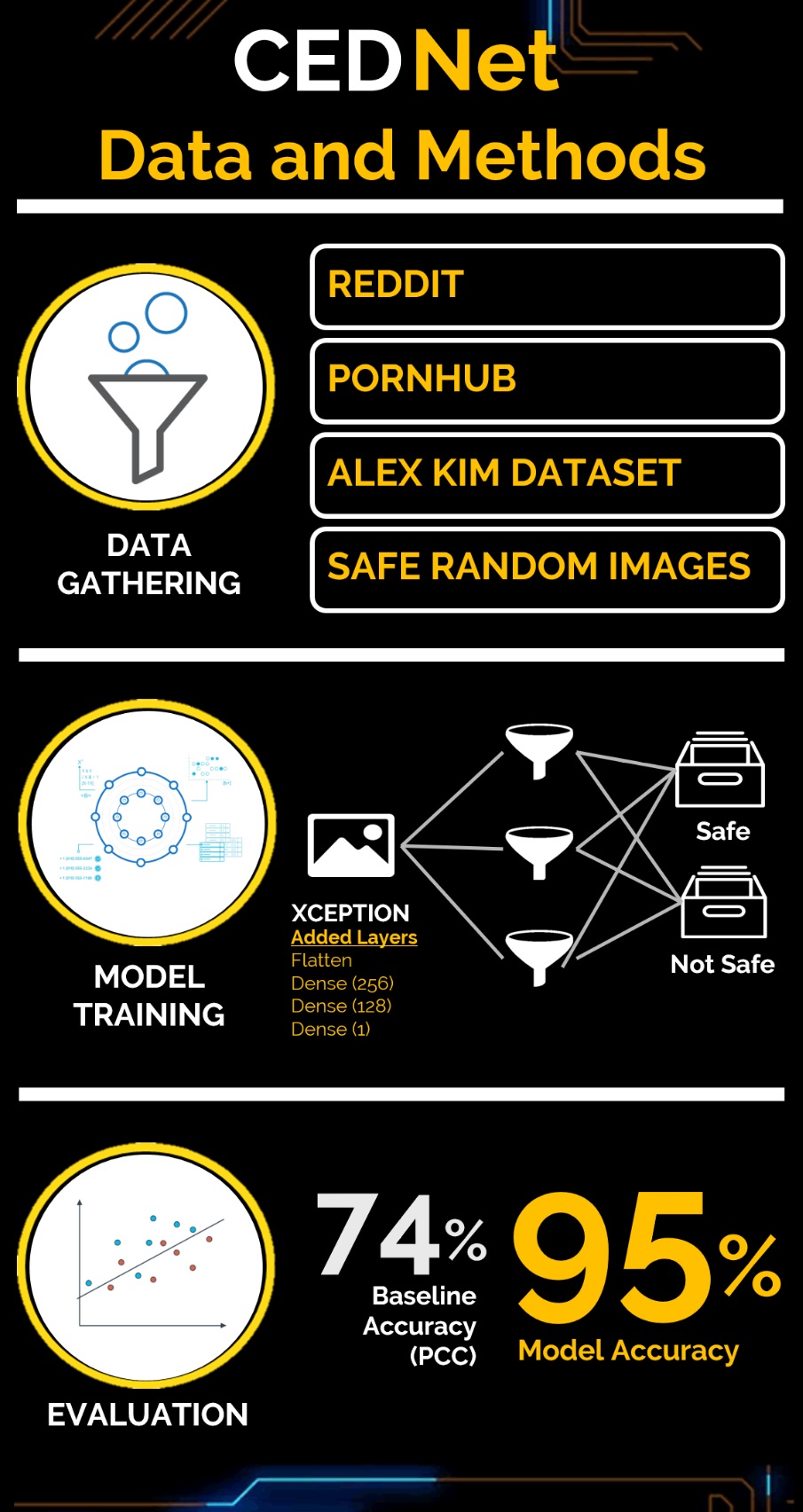
In this study, we created a deep learning model called CEDNet that can automatically classify explicit images. Once tagged as unsafe, the model will automatically censor explicit details in the image. The data set was mined from various websites (i.e., Reddit, Pornhub, Alex Kim Dataset, and Google). With more than 54 million parameters, Xception model was supplemented by four layers was used to train the model. CEDNet was able to classify the images with 95% accuracy, achieving Facebook’s accuracy target for the manual job. Furthermore, CEDNet was tested against a human and found to predict faster for different sets and amount of images.
This model can be scaled to include other censored content and can be used by government authorities like the Movie and Television Review Classification Board as an aid in their rating scheme.
Authors: Cedric Conol, Carmelita Esclanda, Dustin Reyes, Jomilynn Rebanal
Note: For the technical paper (PDF), data and the code used in this project, you may send me an email or you can also drop your message via LinkedIn.