Kwento Beyond Sweldo
Executive Summary
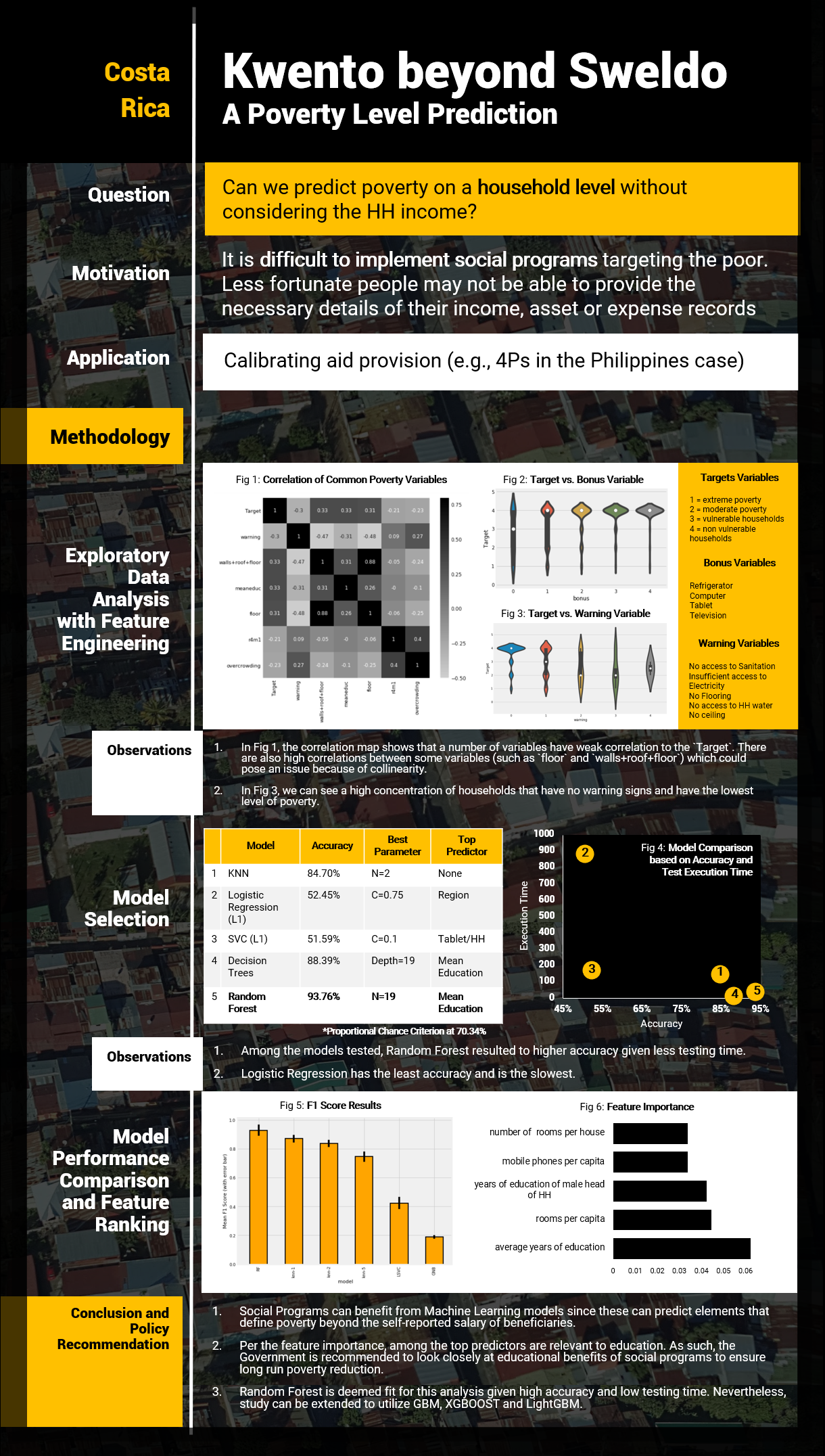
For countries with relatively high level of poverty and budget constraint, funding social programs for the less fortunate is a tedious activity. Self reported surveys and Focus Group Discussions (FGDs) shall be conducted to be able to identify potential benficiaries. Nevertheless, these efforts are not maximized because surveys are self discretionary, thus gives way for knowledgeble populace to take advantage of the program.
Given the said problem, this study intends to test and recommend a Machine Learning approach in identifying Household (HH) poverty levels without considering self-reported income data. Costa Rica dataset from kaggle was used for analysis given that said granular data is not for public consumption in the Philippines.
The ML models compared include K-Nearest Neigbors (KNN), Logistic Regression, Support Vecto Machine-Classifier(SVC), Decision Trees and Random Forest. Random Forest was identified as the best model with 93.76% accuracy and best F1 score. Top relevant features include average years of education, rooms per capita and years of education of Male head of HH. For further studies, GBM and XGBoost models are recommended.
Note: For the technical paper (PDF), data and the code used in this project, you may send me an email or you can also drop your message via LinkedIn.